좋아요 많은 리뷰 Top 10 캐싱 처리 (Redis)를 통한 성능 개선과 부하테스트 결과
1. 해결하고자 하는 문제 상황 및 필요성
이번 팀 프로젝트에서 "좋아요가 많은 상위 10개 리뷰"를 조회하는 기능은 사용자들에게 빈번하게 사용될 것으로 예상되었습니다. 실제 테스트 과정에서도 팀원들이 해당 리뷰 목록 페이지 진입 시 로딩 속도가 체감상 느리다는 의견을 주었고, 이 피드백을 통해 해당 기능의 느린 응답 속도가 데이터베이스 쿼리 성능 문제 때문이라는 것을 알게 되었습니다
해당 기능은 COUNT와 ORDER BY 같은 집계 및 정렬 연산을 포함하고 있어, 데이터베이스(DB)에 상당한 부하를 유발하는 "무거운 쿼리"에 해당합니다. 기존 구조에서는 사용자가 이 정보를 요청할 때마다 DB에 직접 접근해 쿼리를 실행하므로, 동시 접속자 수가 증가할수록 다음과 같은 문제가 발생할 위험이 있었습니다.
- 높은 응답 시간 : DB 쿼리 실행에 시간이 소요되어 사용자가 정보를 받아보기까지 지연 발생
- 낮은 처리량(TPS/RPS) : DB의 처리 한계로 인해 초당 처리 가능한 요청 수 제한
- DB 부하 증가 및 자원 고갈: 전체 서비스 안정성을 위협
이러한 문제들은 사용자 경험 저하로 이어지고, 서비스 확장성에도 제약을 줍니다. 따라서 실제 사용자 피드백과 성능 지표를 근거로, 자주 조회되지만 변경 빈도가 낮은 "좋아요가 많은 상위 10개 리뷰" 데이터에 Redis 캐싱을 적용하여 성능을 개선하는 방안을 도입하게 되었습니다.
2. 선택 기술 및 적합성 설명 (Redis Cache)
팀 프로젝트 일정이 촉박한 상황에서, 프로덕션 환경 수준의 테스트가 어려운 조건을 고려해 빠르게 적용 가능한 Redis 캐시와 로컬 Locust 테스트 방식을 선택했습니다. Redis는 인메모리(In-Memory) 데이터 저장소로서 다음과 같은 장점을 가지므로 해당 상황에 매우 적합합니다.
- 높은 성능: 데이터를 메모리에 저장하고 접근하므로 매우 빠른 읽기/쓰기 속도를 제공합니다. 이는 캐시 히트 시 DB 접근 없이 밀리초 단위의 응답 속도를 달성하는 데 핵심적입니다.
- 스프링 프레임워크 통합 용이성: @Cacheable 등 스프링의 캐시 추상화를 통해 어노테이션 기반으로 쉽게 캐싱을 적용하고 관리할 수 있습니다. 특히 RedisCacheManager를 통해 직렬화/역직렬화 설정을 유연하게 할 수 있어 객체 캐싱에 용이합니다.
이러한 Redis의 특성은 "좋아요가 많은 상위 10개 리뷰"와 같이 빈번하게 조회되는 무거운 쿼리 결과에 대한 요청을 DB까지 도달하지 않고 애플리케이션 서버와 Redis 캐시 사이에서 빠르게 처리함으로써, DB 부하를 획기적으로 줄이고 전반적인 시스템 성능을 향상시키는 데 최적의 선택입니다.
3. 전체 구현 과정 (요약)
- Redis 설치 및 연동: 로컬 PC에 Redis를 설치하고, 스프링 부트 애플리케이션이 Redis와 연결될 수 있도록 의존성 추가 및 application.yml에 Redis 연결 정보를 설정했습니다.
- RedisCacheManager 설정: RedisConfig 클래스를 통해 RedisCacheManager를 빈으로 등록했습니다. 이 과정에서 캐싱될 데이터(리뷰 객체 리스트)의 직렬화/역직렬화 문제를 해결하기 위해 GenericJackson2JsonRedisSerializer를 사용하여 JSON 형태로 데이터를 직렬화하도록 설정했습니다. 이는 향후 데이터 구조 변경에도 유연하게 대처할 수 있도록 합니다.
- @Cacheable 적용: "좋아요가 많은 상위 10개 리뷰"를 반환하는 서비스 메서드에 @Cacheable(value = "top10Reviews", key = "'all'", cacheManager = “cacheManager”) 어노테이션을 적용하여, 해당 메서드가 호출될 때 캐시에 데이터가 있으면 이를 반환하고, 없으면 메서드를 실행하여 결과를 캐시에 저장하도록 했습니다. 이 구조는 향후 '조회수가 많은 콘텐츠'나 '최신 리뷰' 등 다른 고빈도 조회 API에도 동일한 방식으로 확장 및 재사용할 수 있도록 설계되었습니다.
- 로컬 테스트 및 검증:
- Redis 설치 후 캐싱이 정상적으로 작동하는지 확인했습니다.
- 최초 호출 시 DB에 연결되는 것을 확인하고, 이후 반복 호출 시 DB 연결 없이 Redis에서 데이터가 반환되는 것을 redis-cli.exe을 통해 확인했습니다.
- Redis에서 직접 캐시 데이터를 삭제한 후, 다음 호출 시 다시 DB에 연결하여 새로운 데이터가 캐싱되는지 확인했습니다.
4. 성능 개선 전/후 비교
두 가지 시나리오(멤버 100명, 멤버 1000명)에 대해 캐싱 적용 전/후의 Locust 부하 테스트를 진행하여 성능 변화를 측정했습니다. 각 테스트는 5분 동안 진행되었으며, GET /api/reviews/top10 엔드포인트에 대한 요청을 시뮬레이션했습니다.
테스트 환경:
- 로컬 PC 환경: 개발 환경의 한계로 인해 대규모 프로덕션 환경의 부하를 완벽히 재현하기는 어렵지만, 캐싱 효과를 비교하는 데는 충분합니다.
- 더미 데이터: DummyDataGeneratorService를 통해 충분한 더미 데이터(멤버 100명/1000명, 콘텐츠 200개/2000개, 리뷰 10000개/100000개, 리뷰 좋아요 5000개50000개)를 미리 생성하여 DB 부하를 유발할 수 있도록 준비했습니다.
4.1. 시나리오 1: 멤버 100명 콘텐츠200개 리뷰10000개 리뷰좋아요 5000개 환경 (상대적으로 낮은 부하)


캐싱 적용 전 (멤버 100명)
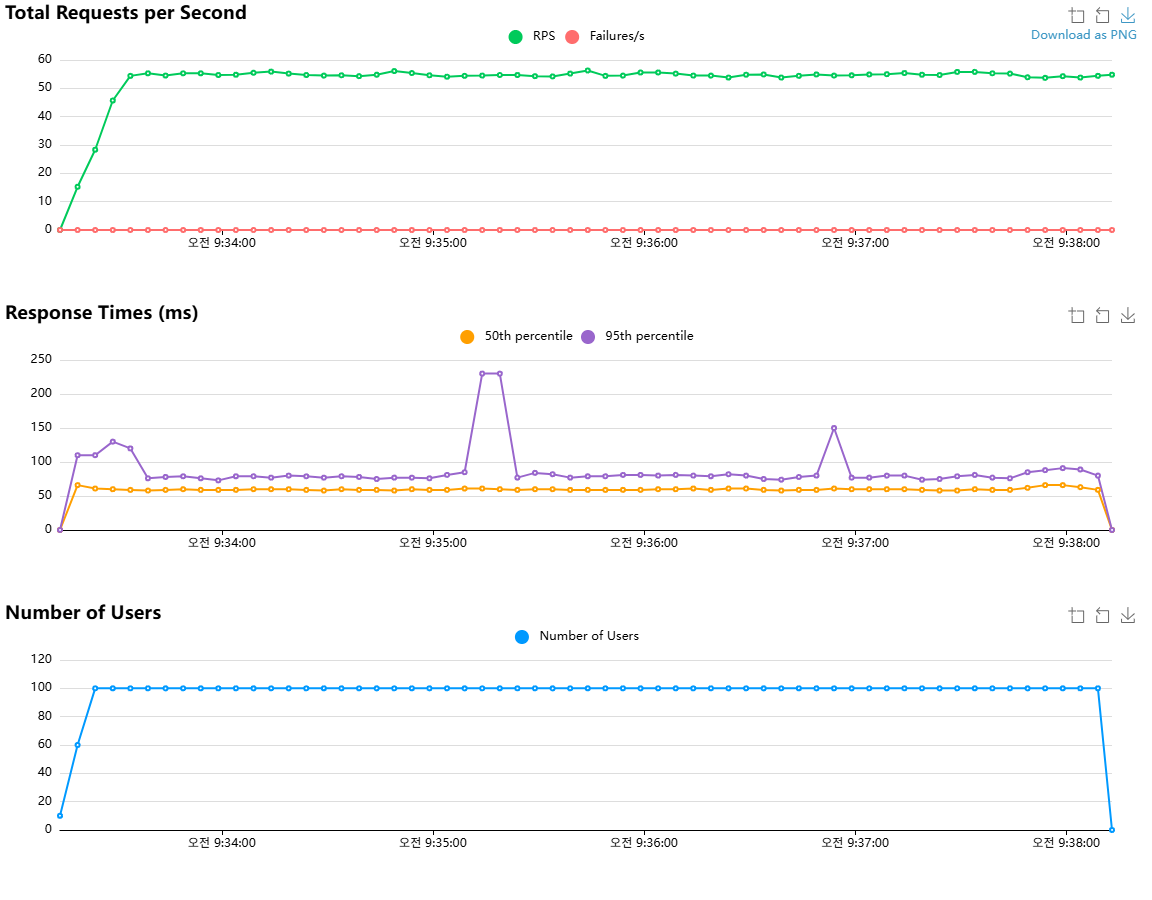
| 평균 응답 시간 | 63.12ms | 요청당 평균 63.12밀리초 소요. |
| 최대 응답 시간 | 720ms | 가장 느린 응답이 0.72초 소요. |
| 50%ile | 60ms | 요청의 절반이 60ms 이내에 완료. |
| 90%ile | 76ms | 요청의 90%가 76ms 이내에 완료. |
| RPS (처리량) | 454.13 | 초당 약 454개의 요청 처리. |
| 총 요청 수 | 162,450 | 5분 동안 처리된 총 요청 수. |
캐싱 적용 후 (멤버 100명)

| 평균 응답 시간 | 2.38ms | 약 26배 감소 (63.12ms → 2.38ms). |
| 최대 응답 시간 | 90ms | 약 8배 감소 (720ms → 90ms). |
| 50%ile | 2ms | 약 30배 감소 (60ms → 2ms). |
| 90%ile | 3ms | 약 25배 감소 (76ms → 3ms). |
| RPS (처리량) | 562.40 | 약 24% 증가 (454.13 → 562.40). |
| 총 요청 수 | 168,730 | 5분 동안 처리된 총 요청 수 (약 6천건 증가). |
분석: 상대적으로 낮은 부하 환경에서도 캐싱은 응답 시간을 압도적으로 단축시켰으며, 처리량 또한 유의미하게 증가했습니다. 특히 최대 응답 시간의 감소는 간헐적으로 발생하는 DB 부하가 크게 줄었음을 시사합니다.
4.2. 시나리오 1: 멤버 1000명 콘텐츠2000개 리뷰100000개 리뷰좋아요 50000개 환경 (상대적으로 낮은 부하)

캐싱 적용 전 (멤버 1000명)
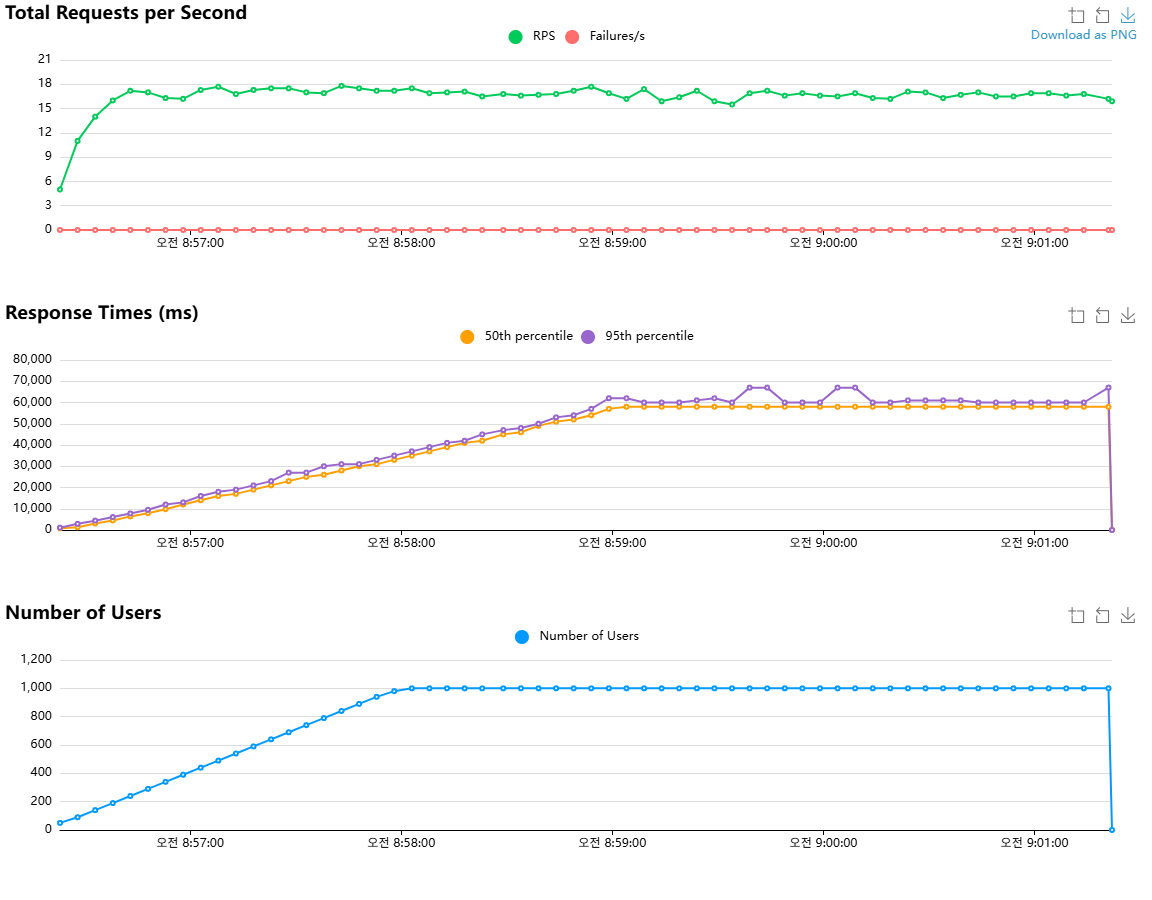
| 평균 응답 시간 | 42606.65ms | 약 42.6초 (DB 부하로 인해 심각한 지연 발생). |
| 최대 응답 시간 | 76000ms | 약 76초 (일부 요청은 1분 이상 대기). |
| 50%ile | 53000ms | 요청의 절반이 53초 이내에 완료. (대부분의 요청이 심각하게 지연) |
| 90%ile | 59000ms | 요청의 90%가 59초 이내에 완료. |
| RPS (처리량) | 116.66 | 초당 약 117개의 요청 처리 (심각한 병목). |
| 총 요청 수 | 50,430 | 5분 동안 처리된 총 요청 수 (낮은 처리량). |
캐싱 적용 후 (멤버 1000명)

| 평균 응답 시간 | 4.27ms | 약 10000배(만 배) 감소 (42606.65ms → 4.27ms). |
| 최대 응답 시간 | 816ms | 약 93배 감소 (76000ms → 816ms). |
| 50%ile | 4ms | 약 13000배 감소 (53000ms → 4ms). |
| 90%ile | 9ms | 약 6500배 감소 (59000ms → 9ms). |
| RPS (처리량) | 475.87 | 약 4배 증가 (116.66 → 475.87). |
| 총 요청 수 | 142,859 | 5분 동안 처리된 총 요청 수 (약 3배 증가). |
분석: 멤버 1000명 환경에서 캐싱의 효과는 극적입니다. 캐싱 적용 전에는 DB에 과도한 부하가 발생하여 응답 시간이 수십 초에 달하고 처리량이 매우 낮았습니다. 캐싱 적용 후에는 응답 시간이 평균 4ms대로 떨어지고 처리량은 4배 이상 증가했습니다. 이는 캐싱이 심각한 DB 병목 현상을 성공적으로 해결했음을 명확하게 보여줍니다.
5.1. 개발 과정 회고
- 기대 이상의 효과 확인
- Redis 캐싱을 적용하기 전과 후의 성능 지표 차이를 통해, 캐싱이 얼마나 강력한 효과를 발휘하는지 직접 확인할 수 있었습니다.
- 직렬화/역직렬화의 중요성
- RedisCacheManager 설정 과정에서 직렬화에 대한 이해와 해결이 중요하다는 점을 다시금 느꼈습니다. 객체를 Redis에 저장하고 다시 읽어올 때 적절한 직렬화 방식을 사용하지 않으면 오류가 발생할 수 있다는 점을 체감했습니다.
5.2. 로컬 환경 한계점과 개선 방안
로컬 환경의 한계
로컬 PC 환경에서 진행한 부하 테스트는 캐싱 적용 전후의 성능 차이를 확인하는 데 있어 매우 유의미했습니다. 특히 Redis 캐싱이 무거운 쿼리로 인한 DB 부하를 효과적으로 회피하며 성능을 개선했다는 사실을 입증하는 데 큰 도움이 되었습니다.
하지만 테스트 과정에서 100명과 1000명 동시 사용자 시나리오 간의 성능 차이가 지나치게 극단적으로 나타났고, 해당부분을 학습 결과 이는 로컬 환경의 본질적인 한계 때문이라는 점을 알게 되었습니다. 로컬 환경에서는 다음과 같은 이유로 인해 대규모 부하 테스트 시 더욱더 극단적으로 차이가 나게 됩니다
- 제한된 자원
- 로컬 PC는 CPU 코어 수, 메모리 용량, 디스크 I/O 속도 등에서 실제 서버 환경보다 자원이 제한적입니다. 1000명의 동시 접속을 시뮬레이션할 경우, DB커넥션풀과 자바 힙 메모리 자원이 금세 고갈되어 병목 현상이 발생하고 응답 속도가 비정상적으로 느려질 수 있습니다.
- 단일 머신 구성
- 애플리케이션 서버, 데이터베이스, Redis, 부하 테스트 도구(Locust)까지 모두 하나의 로컬 PC에서 실행되기 때문에 자원 경쟁이 심해집니다. 이는 각 구성 요소가 독립된 서버에 분리되어 배포되는 실제 운영 환경과는 큰 차이를 만듭니다.
개선 방안
- 클라우드 기반 부하 테스트 도구 활용 (아쉬운 점)
- 실제 운영 환경에서의 대규모 동시 접속을 보다 현실적으로 시뮬레이션하려면 AWS Load Generator, JMeter의 분산 모드 등 클라우드 기반 부하 테스트 도구를 활용하는 것이 이상적입니다. 다만, 이번 팀 프로젝트에서는 예산의 제약으로 인해 AWS 환경에서 직접 실험하지 못한 점이 아쉬움으로 남습니다.
6. 마지막 소감
이번 캐싱 처리는 "리뷰 좋아요 Top 10 조회" 기능에서의 성능 병목을 성공적으로 해결했으며, 향후 서비스 확장 시 발생할 수 있는 잠재적인 문제를 사전에 방지할 수 있는 기반을 마련했습니다. 지속적인 모니터링과 캐싱 전략의 최적화를 통해, 실제 환경에 가까운 테스트를 거쳐 더욱 견고하고 효율적인 시스템으로 발전시켜 나갈 수 있을 것으로 기대합니다.
7. 추가 학습 내용
DB 커넥션 풀(Database Connection Pool) 과 자바 힙 메모리(java Heap Memory) 설정 변경 학습
100명과 1000명 사용자 테스트에서 성능차이가 극심하게 나타난다면, DB 커넥션풀(Database Connection Pool)과 자바 힙 메모리(Java Heap Memory) 가 원인 중의 하나일 가능성이 있음을 학습하고 성능개선 방법에 대한 내용을 다음에 정리해두었습니다.
1. Java Heap Memory (JVM 힙 메모리) 설정을 변경하여 성능개선을 할 수 있습니다
JVM이 사용할 수 있는 최대 힙 메모리 크기( -Xmx)를 늘릴 경우 성능개선을 할 수 있습니다

2. MySQL DB 커넥션 풀의 크기 설정을 변경하여 성능개선을 할 수 있습니다.
application.yml 파일에서 데이터베이스 커넥션 풀의 크기 설정을 상향 조정할 수 있습니다

동시 요청이 몰릴 때 DB커넥션 풀에 사용 가능한 연결이 없으면, 요청은 연결이 반납될 때까지 대기해야합니다. maximum-pool-size를 늘리면 더 많은 요청을 대기 없이 동시에 처리할 수 있어 응답 시간이 크게 개선됩니다
Redis 커넥션 풀 설정을 상향조정하여 성능 개선을 할 수 있습니다
Redis 역시 DB처럼 커넥션 풀을 사용합니다. 부하가 높을 때 Redis 명령이 느려진다면 Redis 커넥션 풀이 부족한 것일 수 있습니다.
application.yml 파일에서 Lettuce (스프링 부트 기본 Redis 클라이언트)의 커넥션 풀 설정을 상향조정합니다
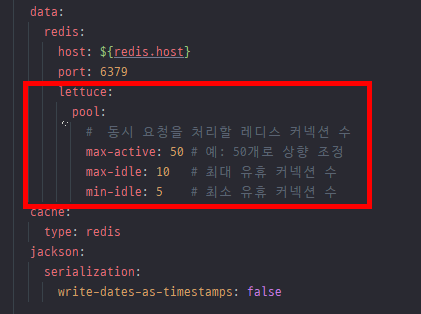
MySQL 과 마찬가지로, 동시에 Redis에 접근하려는 요청이 많아 지면 Redis커넥션 풀이 고갈될 수 있습니다. max-active 값을 늘려주면 더 많은 요청이 Redis에 동시 접근하여 원할하게 데이터를 읽고 쓸 수 있습니다.
'트러블슈팅,기술적의사결정' 카테고리의 다른 글
| 리뷰 조회 성능 개선 : JPA N+1 문제 해결을 통한 리뷰 조회 성능 개선 (3) | 2025.07.10 |
|---|---|
| 리뷰 수정 시 존재하지 않는 리뷰인데 500에러 발생(트러블 슈팅) (1) | 2025.07.09 |
| 일정관리디벨롭 CalendarDevelop 프로젝트 회고와 트러블 슈팅 (0) | 2025.04.04 |
| 일정관리 앱 만들기 프로젝트 README와 트러블슈팅 (1) | 2025.03.26 |
| 키오스크화면만들기 트러블슈팅과 소감 (1) | 2025.03.14 |